
 大城 海斗
大城 海斗
データアナリスト / いけばなとキーボードが趣味
以下 あおもじ 髙嶺 潮
髙嶺 潮
データアナリスト / 伊江島生まれの伊江島育ち
以下 みちる先生
 幸地 彩子
幸地 彩子
採用広報 / 虫大好き
以下 こうち
2022 年 3 月開催の情報処理学会 第 84 回全国大会で、ちゅらデータ社員が発表をします。タイトルは『軽量な OCR モデルの予測確信度と言語モデルを利用した日本語手書き文字認識結果の事後訂正』。今回、その発表者である『あおもじさん』にインタビューをして、社内で研究をした困難や、普段の仕事のことなどを伺いました。
途中から読みたい方はこちら
今回発表をするあおもじさんってどんな仕事をしているんですか?

早速ですがあおもじさんがちゅらデータに入社した経緯など教えて下さい!
2019 年の 4 月に新卒で入社しました。実は最初からちゅらデータのことを知っていたわけではなくて、2017 年の 5 月ごろに DATUM STUDIO でインターンをしたあと、真嘉比さんと面談することがあったのが入社のきっかけでした。 東京でインターンしてまさか沖縄の会社に誘われるとは思わなかったです 笑

今はどういう仕事をちゅらデータでしていますか?
Python をメインで使っていて、今までやってきた案件だとディープラーニングを扱ったので TensorFlow とか Keras を使っていました。 案件は、僕自身がやってみたいことに手を挙げて、それでやらせてもらうっていう流れだったので、ディープラーニングの案件ばかりというわけでもないです。 今は、ウェブのポータルサイトづくりに携わっています。新しいコンテンツを作成するために裏側でデータを集めたり、サイトの UI でどのパターンが一番効果が高いか検証するときに効果を測るログ分析などをやっています。
今回の研究発表が生まれた経緯
あれ? そしたら今回研究発表するのはまったく別の業務ですか?
はい、そうです。今回「情報処理学会 第 84 回全国大会」で発表するのはまた別のプロジェクトなんです。 「受託分析だけでなく、研究もできて自社プロダクトも作れるような環境をちゅらデータに作りたい」「そのために技術力を磨いて、磨いた技術力をちゃんと発信していきたい」と真嘉比さんが思っていて、その中でスタートしたのが今回の発表につながる OCR プロジェクトでした。 OCR 自体が、文字を認識する画像処理の他に、文字列を訂正するための自然言語処理など、横断的で幅広い技術が必要になるチャレンジングな分野だったんです。新しいこといっぱい始めちゃおうぜ!みたいなプロジェクトです 笑 今もプロダクトをつくる社内プロジェクトと R&D の社内プロジェクトがあって、各種進行中ですよ!
じゃあ今回の発表は、業務としてチームで取り組んできたんですね。
そうなんです、チーム全員がいたから今回の研究ができました。社員のほかに学生さんにも多く関わってもらっています。学生さんはやっぱり考えが柔軟で、ポンポンアイディア出てきて「その発想はなかった」と助けられることも多かったです。 今回の発表でも、たくさんの方からバンバンコメントほしいなと思ってます!(お陰様で4件の質疑をいただきました、聴講くださった皆さまありがとうございました!)
学生さんも社員と一緒に研究に関われるってすごく良い環境だなと思います。
今回の発表内容について
ここからはみちる先生も交えて技術的な部分にも踏み込んで伺います! 早速ですが今回の発表の中身を教えてください。
どうして今回の研究をしたのか
『軽量な OCR モデルの予測確信度と言語モデルを利用した日本語手書き文字認識結果の事後訂正』というタイトルで、ずばり OCR モデルの研究をしました。
社内事情であまり具体的にお伝えできませんが、目的の1つにちゅらデータの技術力向上があります。
OCR をビジネス活用するには、文字認識させるための領域検知や画像処理の技術に加え、認識結果の文字列が誤っている場合は訂正する自然言語処理技術も必要となります。
幅広い技術が求められるため、社内的にもチャレンジングな試みとなりました。
研究の推しポイント

世の中にすでにある OCR モデルと、今回発表したモデルはどういったところが違うんですか?
OCR 結果を訂正して正しい文字列にするものは、すでに研究として、製品としてあったんです。
通常は、OCR 結果の文字列だけを見て『訂正モデル』が訂正する方法ですが、今回の研究では、『訂正モデル』だけでなく『OCR モデル』から得られる文字の正しさの度合いを利用して訂正処理を行いました。
文字の正しさの度合いを活用して、ビジュアル的に似ている訂正候補の文字を選択し直す、という仕組みです。
OCR で読み込んだとき、実際に書かれている文字と出力された結果が間違っていた場合を確認すると、博士の『士』と、あとは土星の『土』、のような感じで似た文字に間違えているんですね。確かに似てるじゃないですか 笑
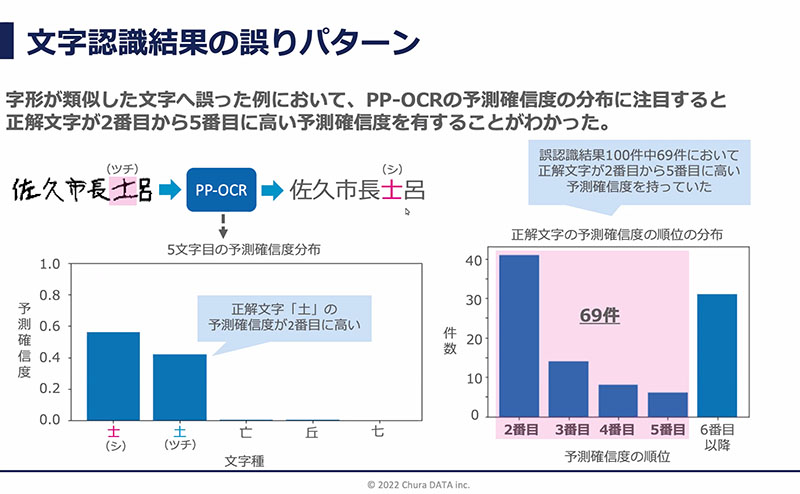
似た文字に間違えるケースが、誤りの半数以上を占めることもあったので、似た文字に間違えるケースをうまく訂正したいよねと、そういうアプローチになりました。
今までの事後訂正では、(上転載スライド参照)例えばさくし(佐久市)っていうのは地名なので、おそらく後に続く文字も地名だろうね? という推察から、地名らしい名前っていうのを地名らしい文字の並びになるように訂正するのが言語モデルの役割でした。 今回の論文ではそれに加えて、OCR モデルで出てきた『文字の確信度の分布』情報もつかって、訂正文字列を選択していく、という流れになっています。
文脈を汲んでくれるのが言語モデルなんですが、ルックス的な見た目で文字の類似度を考慮する場合、あわせて OCR の予測確信度を利用すると、類似する文字の中から文脈的にもっともらしい文字を選択することができるわけです。
今までは単純に文字のアウトプット情報だけから訂正しようと試みていたものを、その文字を出す過程の機械の「思考」の途中経過まで考慮したのが今回のモデルということですか?
そうです!
機械の途中の思考というのが、この予測確信度にあたるわけです
研究の困ったこと
研究といえば苦労話がつきものかと思いますが、あればぜひ教えて下さい。
苦労したことで言うと、本物の手書き文字とか学習していない手書き文字とかを試しに予測させてみると、まあ当たらないんですよ! 簡単な数字とかは読み取るんですけど、漢字とか平仮名が混じると一部がやっぱり読み込めない。というか認識できないんですね。
今回の手書き文字のデータは、実際に人から集めるのはかなり苦労があるので人工的に生成したものを使ったんです。 生成した手書き文字画像は文字数がたかだか 10 文字ぐらいとある程度決まっているんですが、それよりも多い文字数を与えるとやっぱりうまく認識できないことが起きていました…
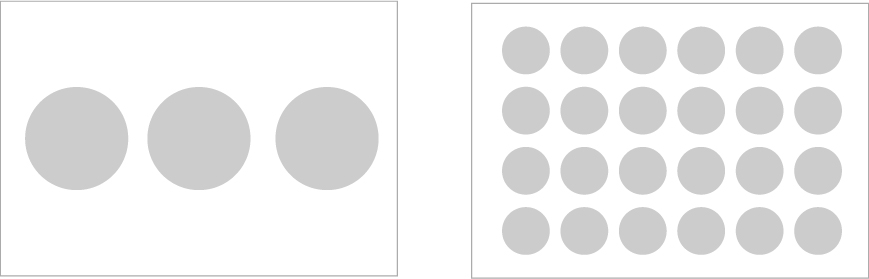
与えられる画像サイズが実は決まっているんです。
例えば 3 文字だったらその画像の中で大きめに入っていますが、文字数が多くなるほど文字が小さくなります。
小さくなったその一文字が、画像中でどれくらいのサイズを占めているかを判定するところで、データの準備が甘くて学習できていないのかなということがありました(上図参照)。
文字数が多くなると文字が欠落して一文字読めていないとか、そういうことが起きてしまって、一文字の単位をうまく認識できないっていう…
とても悔しかったです!!
研究の楽しかったこと
ぜひ研究の楽しかった話も教えて下さい!
楽しかったところでいうと、やっぱり実際に文字がきれいに読み取れると、おお! やっぱすごいな! という気持ちになります 笑 うまく歩けない子どもを見守るような感じがあります。愛着があるので、今後も育てていきたいですね。
研究の今後の展望
さらなる精度改善のアイディアとか、今回の技術を活かした応用の話とか、今後こんなことがこの結果で新たにできるようになるとか、そういう展望があればぜひ教えてください。
はい、今後やりたいなと思っていることがいくつかあります。
ひとつが、文字の検出ができるモデルをちゃんと作りたいということ。
作った OCR モデルは切り出した文字を与えているので、文字を切り出す手間があります。ですから、大きな全体からどこに文字があるのかを見つける技術がさらに必要になってくると思っています。
ふたつめは、今回は事後訂正の技術を入れたモデルについて発表しましたが、事後訂正できる誤りのパターンは限られているので、OCR モデル自体の精度向上もやっていけたらと思っています。 他にも、今回の論文では小さくて軽量に動作する OCR 技術の開発も目的の一つだったのですが、実際には事後訂正するモデルのサイズが大きかったので、事後訂正モデルの軽量化も今後やっていきたいと思ってます。
どのぐらいのデータサイズを想定しているんですか?
今回つくった事後訂正をする言語モデルが、大きいもので 3 GB ぐらい。それは大きいなぁと…
数十 MBぐらいまで落とし込めたらいいかなと思っています。または、そういう言語モデルを見つけて仮に使うとか。何らかの工夫で軽量化を図れたらと思ってます。
ちゅらデータのいいところ
研究発表までこなすあおもじさんに「ちゅらデータのいいところ」ぜひ聞きたいです!
何よりもまず雰囲気が良いですね…雑談が楽しくて、でもやることはちゃんとやる、みたいな。大学の研究室をちょっと思い出します 笑 雑談はリモートワークもあってslackが主ですけど、ちゅらデータには面白いこと言う人がいるのでよく笑ってます。あまり僕は何か喋ったりつぶやいたりするタイプじゃないので、ずっと読んでたりするだけなんですけど。 そういうのだけじゃなくて、業務で何か調べたこととか学んだこととかって共有していく学びの雰囲気があるのもいいかなぁと。
わかります、「トイレで抜けます」っていう正直なメッセージ見て感心したことを思い出します。
あと、リモートワークが始まってからは家のことも気にかけながら仕事できるのがやっぱり良いですね。家のことをするためにカジュアルに「ちょっと離席します」って言える。僕に限らず他のメンバーでも、例えばお子さんが熱だしたとか、ちょっとお迎えいかなきゃとか、そういうときでもわかってくれて気持ちよく送り出してくれるのは良いところだなと日々思っています。
リモートワークだからこそ、何をしているのか共有するためのコミュニケーションがきっちり機能しているのは大事ですよね。 仕事上、ちゅらデータでやりがいとか楽しさを感じるのはどんな点ですか?
今やっている案件自体も楽しいですね。こういう風にポータルサイトって作られてるんだとか、このスピード感なんだとか。 これまでやってきたのが分析や研修の案件で、どちらかというとエンジニアリングの面が強かったんです。それでちょっと別なところにチャレンジしてみたいなっていう気持ちで今の案件に参加しました。今の案件はやはり発見や驚きが多くて、とても新鮮で面白いです。 ちゅらデータで働いてると、自分で手を挙げていろいろな案件に関われるので、毎回新鮮な気持ちでいられるんじゃないかなと思います。
We are Hiring!








